Pandas常用方法
记录一些pandas常用的操作,会持续更新
1.创建Dataframe
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(d)
print(df)
print("-" * 35)
d2 = [{"name": "bob", "age": 12}, {"name": "alice", "age": 9}]
df2 = pd.DataFrame(d2)
print(df2)
print("-" * 35)
df3 = pd.DataFrame([['a', 10, '男'], ['b', 11, '女']], columns=['name', 'age', 'gender'])
print(df3)
2.cannot reindex from a duplicate axis报错
df[df.index.duplicated()]获取index重复的行。
删除重复的行:
df.drop_duplicates(subset=['nav_date'], inplace=True),删除nav_date列重复数据的行。
3.交并补
df1 = pd.DataFrame([['tom', 10, '男'], ['alice', 11, '女']], columns=['name', 'age', 'gender'])
df2 = pd.DataFrame([['tom', 10, '男'], ['ben', 12, '男']], columns=['name', 'age', 'gender'])
print(df1)
print(df2)
# 交集
df_intersect = pd.merge(df1, df2, on=['name', 'age', 'gender'], how='inner')
print("intersect:", "-" * 35)
print(df_intersect)
# 并集
print("union:", "-" * 35)
df_union = pd.concat([df1, df2])
df_union.drop_duplicates(inplace=True)
print(df_union)
# 差集
print("subtract:", "-" * 35)
df_subtract = pd.concat([df1, df2])
df_subtract.drop_duplicates(keep=False, inplace=True)
print(df_subtract)
4.df1不在df2中的数据
df1 = pd.DataFrame([['tom', 10, '男'], ['alice', 11, '女']], columns=['name', 'age', 'gender'])
df2 = pd.DataFrame([['tom', 10, '男'], ['ben', 12, '男']], columns=['name', 'age', 'gender'])
print(df1)
print(df2)
df = pd.merge(df1, df2, on=['name', 'age', 'gender'], how='left', indicator=True)
df = df.loc[df['_merge'] == 'left_only']
print(df)
5.date_range
可以创建一段连续的时间数据
index = pd.date_range(start='2022-05-01', end='2022-05-3', freq='D')
print(index)
df = index.to_frame(index=False, name='candle_begin_time')
print(df)
freq还有很多种格式,具体参考:https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases
6.resample
时间序列重构,可以对时间重新采样。
使用要点:
- dataframe的index需要是DateIndex
- 新版本的pandas推荐使用offset代替base,offset写的时候需要带上时间单位,也是参考data_range的freq即可。
# 创建数据
index = pd.date_range(start="2022-05-01 00:00:00", end="2022-05-01 23:59:00", freq='T')
df = index.to_frame(name='candle_begin_time', index=False)
df['num'] = 1
df.set_index('candle_begin_time', inplace=True)
print(df)
# resample到4个小时
df_hour = df.resample(rule='4H').sum()
print(df_hour)
# resample到4个小时,offset2个小时
#print("-" * 35)
#df_hour = df.resample(rule='4H', base=2).sum()
#print(df_hour)
# 新版中要使用offset代替base,而且offset需要写具体单位
print("-" * 35)
df_hour = df.resample(rule='4H', offset='2H').sum()
print(df_hour)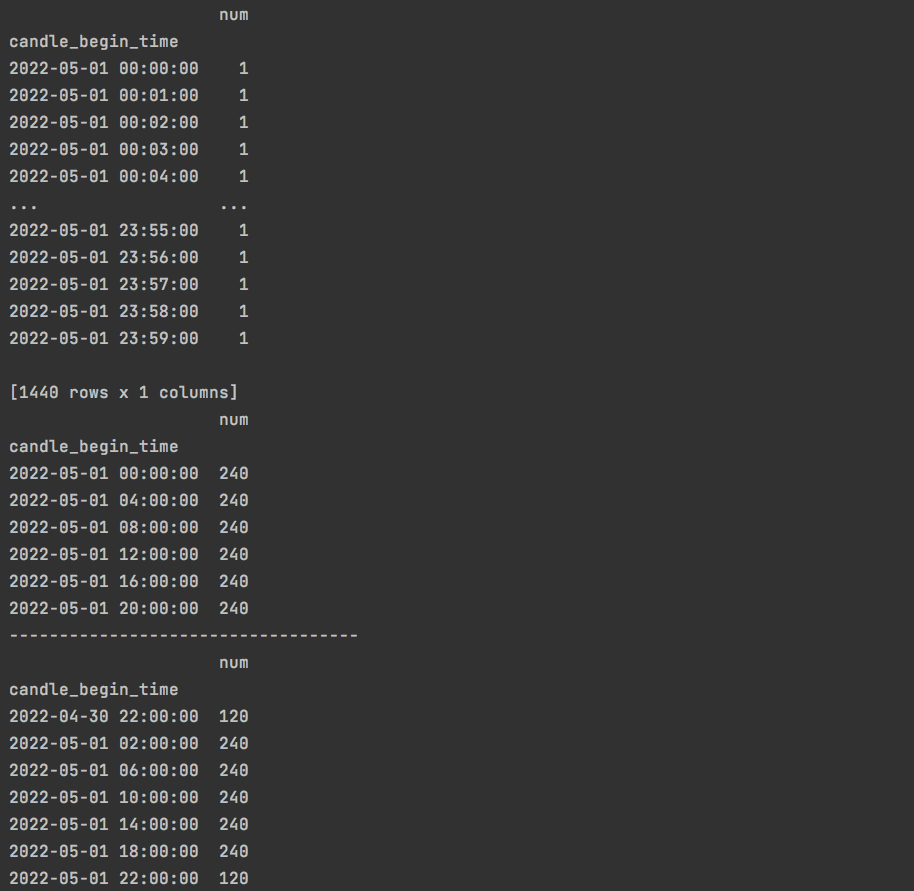
7.数据类型转换
把string类型的列转换为float
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
print(df.dtypes)
df['col2'] = df['col2'].astype('float')
print("-" * 35)
print(df.dtypes)
df['col1'] = pd.to_numeric(df['col1'])
print("-" * 35)
print(df.dtypes)
df['col1'] = pd.to_numeric(df['col1'], downcast='float')
print("-" * 35)
print(df.dtypes)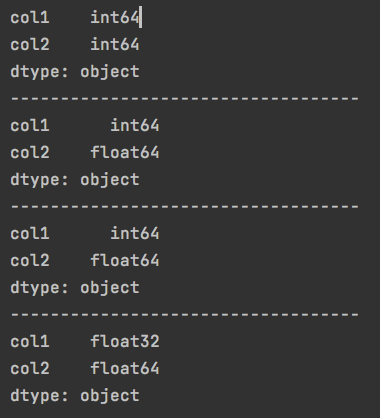
8.百分比字符串转为float
df = pd.DataFrame(['50%', '75%'], columns=['percents'])
print(df)
df['percents'] = df['percents'].str.strip('%').astype(float) / 100
print(df)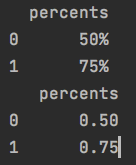
9.aggregate多个
groupby之后用agg操作的话,是可以指定数组来计算的。
df_group = df.groupby(by=['factors_str']).agg(
{"累积净值": "mean", "年化收益/回撤比": "median", "offset_count": "sum", "最大回撤": ["max", "min"]})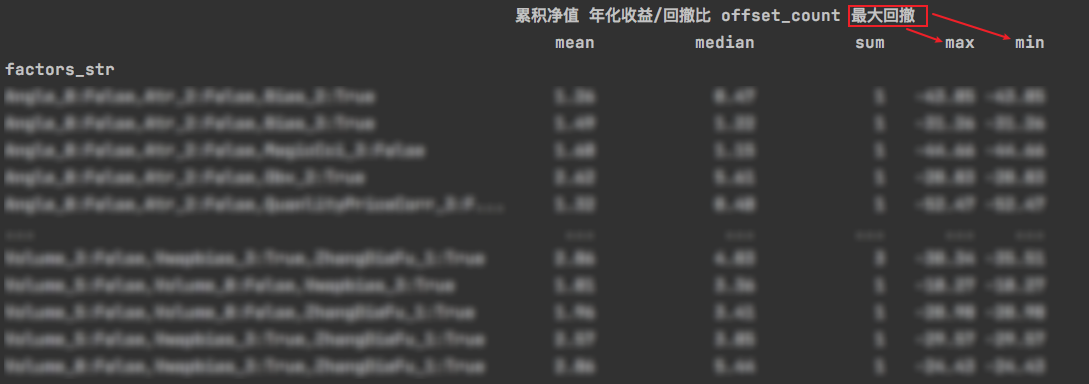
10.Cannot index with multidimensional key
如9中的dataframe,column是有两层的。这时候直接df.loc[df['offset_count'] == 1]也是操作不了的,会报错。
有几种方法来对column进行操作。
1.get_level_values
df_group.columns = df_group.columns.get_level_values(0)
2.to_flat_index
df_group.columns = df_group.columns.to_flat_index()
3.map
df_group.columns = df_group.columns.map('_'.join)
4.to_flat_index& lambda
df_group.columns = [f"{x}_{y}" if y != "" else f"{x}" for x, y in df_group.columns.to_flat_index()]
11.把一列数组转换为多行
df = pd.DataFrame(
{'trial_num': [1, 2, 3],
'subject': [1, 1, 1],
'samples': [list(np.random.randn(3).round(2)) for i in range(3)]
}
)
print(df)
s = df.apply(lambda x: pd.Series(x['samples']), axis=1).stack().reset_index(level=1, drop=True)
s.name = 'sample'
df = df.drop('samples', axis=1).join(s)
print(df)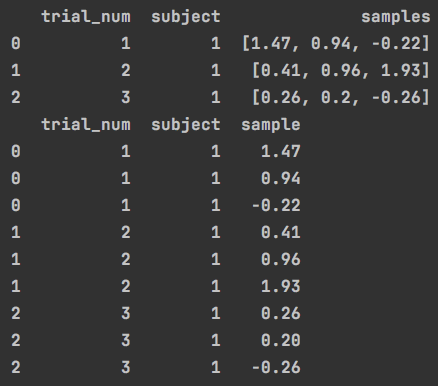
12.筛选某一列值重复2次以上的行
df = pd.DataFrame({'a': [0, 0, 0, 1, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4]})
# 筛选
df[df['a'].isin(df['a'].value_counts()[df['a'].value_counts()>2].index)]13.导出到excel时附带超链接
# link=https://www.baidu.com
df['link'] = df['link'].apply(lambda x: f'=HYPERLINK("{x}", "{x}")') # excel超链接14.判断列数据是否都为nan
for col in df.columns:
empty = pd.isnull(df[col]).all()
if empty:
print(col, '为空')